News Feed (e.g. Facebook)
Companies
Designing a news feed application is a classic system design question, but almost no existing resource discusses in detail about how to design the front end of a news feed.
Question
Design a news feed application that contains a list of feed posts users can interact with.
Real-life Examples
Requirements Exploration
What are the core features to be supported?
- Browse news feed containing posts by the user and their friends.
- Liking and reacting to feed posts.
- Creating and publishing new posts.
Commenting and sharing will be discussed further down below but is not included in the core scope.
What kind of posts are supported?
Primarily text and image-based posts. If time permits we can discuss more types of posts.
What pagination UX should be used for the feed?
Infinite scrolling, meaning more posts will be added when the user reaches the end of their feed.
Will the application be used on mobile devices?
Not a priority, but a good mobile experience would be nice.
Architecture/High-level Design
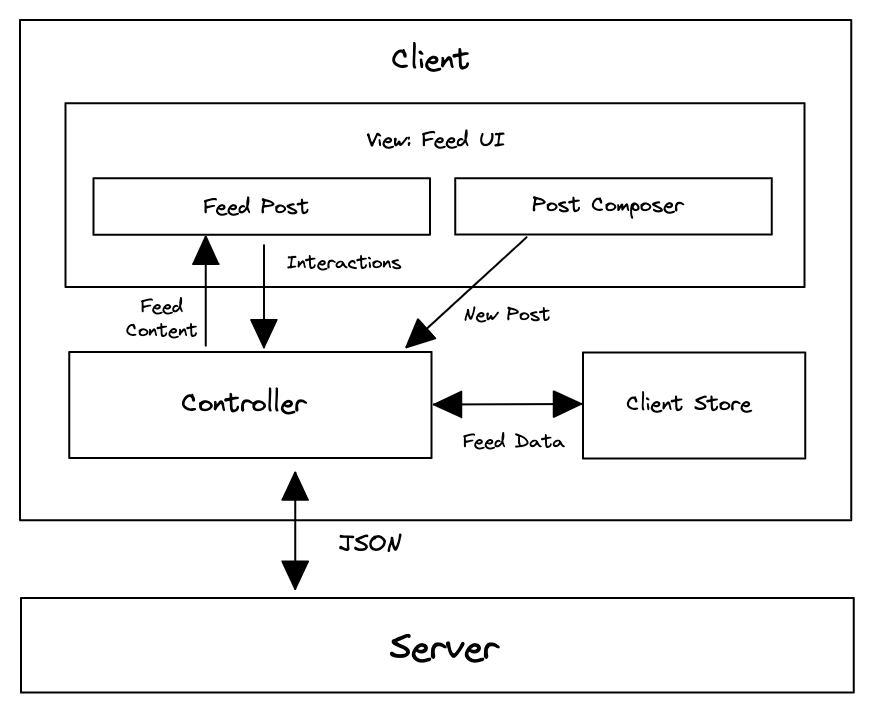
Component Responsibilities
- Server: Provides HTTP APIs to fetch feed posts and to create new feed posts.
- Controller: Controls the flow of data within the application and makes network requests to the server.
- Client Store: Stores data needed across the whole application. In the context of a news feed, most of the data in the store will be server-originated data needed by the feed UI.
- Feed UI: Contains a list of feed posts and the UI for composing new posts.
- Feed Posts: Presents the data for a feed post and contains buttons to interact with the post (like/react/share).
- Post Composer: WYSIWYG (what you see is what you get) editor for users to create new feed posts.
Data Model
A news feed shows a list of posts fetched from the server, hence most of the data involved in this application will be server-originated data. The only client-side data needed is form state for input fields in the post composer.
| Entity | Source | Belongs To | Fields |
|---|---|---|---|
Feed | Server | Feed UI | posts (list of Posts), pagination (pagination metadata) |
Post | Server | Feed Post | id, created_time, content, author (a User), reactions, image_url (for posts containing images) |
User | Server | Client Store | id, name, profile_photo_url |
NewPost | User input (Client) | Post Composer UI | message, image |
Although the Post and Feed entities belong to the feed post and feed UI respectively, all server-originated data can be stored in the client store and queried by the components which need them.
The shape of the client store is not particularly important here, as long as it is in a format that can be easily retrieved from the components. New posts fetched from the second page should be joined with the previous posts into a single list with the pagination parameters (cursor) updated.
Advanced: Normalized Store
Both Facebook and Twitter use a normalized client side store. If the term "normalized" is new to you, have a read of Redux's documentation on normalizing state shape. In a nutshell, normalized data stores:
- Resemble databases where each type of data is stored in its own table.
- Each item has a unique ID.
- References across data types use IDs (like a foreign key) instead of having nested objects.
Facebook uses Relay (which can normalize the data by virtue of knowing the GraphQL schema) while Twitter uses Redux as seen from the "Dissecting Twitter's Redux Store" blog post.
The benefits of having a normalized store are:
- Reduce duplicated data and have a source of truth for the same piece of data that could be presented in multiple instances on the UI. E.g. if many posts are by the same author, we're storing duplicated data for the
authorfield in the client store. - Easily update all data for the same entity. In the scenario that the feed post contains many posts authored by the user and the user changes their name, it'd be good to be able to immediately reflect the updated author name in the posts. This will be easier to do with a normalized store than a store that just stores the server response verbatim.
In the context of an interview, we don't really need to use a normalized store for a news feed because:
- With the exception of the user/author fields, there isn't much duplicated data.
- News feed is mostly for consuming information, there aren't many use cases to update data.
- Feed user interactions such as liking only affect data within a feed post.
Hence the upsides of using a normalized store is limited. In reality, Facebook and Twitter websites contain other features, so a normalized store is useful in reducing storing of duplicate data and provides the ease of making updates.
Further reading: Making Instagram.com faster: Part 3 — cache first
Interface Definition (API)
| Source | Destination | API Type | Functionality |
|---|---|---|---|
| Server | Controller | HTTP | Fetch feed posts |
| Controller | Feed UI | JavaScript | Transfer feed posts data, Reactions |
| Controller | Server | HTTP | Create new post |
| Post Composer | Controller | JavaScript | Transfer new post data |
The most interesting API to talk about will be the HTTP API to fetch a list of feed posts because the pagination approach is worth a discussion. The HTTP API for fetching feed posts from the server has the basic details:
| Field | Value |
|---|---|
| HTTP Method | GET |
| Path | /feed |
| Description | Fetches the feed results for a user. |
There are two common ways to return paginated content, each with its own pros and cons.
- Offset-based pagination
- Cursor-based pagination
Offset-based Pagination
An offset-based pagination API accepts the following parameters:
| Parameter | Type | Description |
|---|---|---|
size | number | Number of results per page |
page | number | Page number to fetch |
Given 20 items in a feed, parameters of {size: 5, page: 2} will return items 6 - 10 along with pagination metadata:
{"pagination": {"size": 5,"page": 2,"total_pages": 4,"total": 20},"results": [{"id": "123","author": {"id": "456","name": "John Doe"},"content": "Hello world","image": "https://www.example.com/feed-images.jpg","reactions": {"likes": 20,"haha": 15},"created_time": 1620639583}// ... More posts.]}
and the underlying SQL query resembles:
SELECT * FROM posts LIMIT 5 OFFSET 0; -- First pageSELECT * FROM posts LIMIT 5 OFFSET 5; -- Second page
Offset-based pagination has the following advantages:
- Users can jump to a specific page.
- Easy to see the total number of pages.
- Easy to implement on the back end. The offset for a SQL query is calculated using
(page - 1) * size.
However, it also comes with some issues:
For data that updates frequently, the current page window might be inaccurate after some time. Imagine a user has fetched the first 5 posts in your feed. After sometime, 5 more posts were added. If the users scroll to the bottom of the feed and fetches page 2, the same posts in the original page 1 will be fetched, and the user will see duplicate posts.
// InitiallyPosts: A, B, C, D, E, F, G, H, I, J^^^^^^^^^^^^^ Page 1 contains A - E// New posts added over timePosts: K, L, M, N, O, A, B, C, D, E, F, G, H, I, J^^^^^^^^^^^^^ Page 2 also contains A - E
The client can be smart about it and de-duplicate posts, not showing posts that are already visible, but the client will have to make a new request for new posts which is an extra roundtrip.
Another downside of offset-based pagination is that you cannot change the page size for subsequent queries since the offset is a product of the page size and the page being requested.
| Page | Page Size | Results |
|---|---|---|
| 1 | 5 | Items 1 - 5 |
| 2 | 5 | Items 6 - 10 |
| 2 | 7 | Items 8 - 14 |
In the above example, you will be missing out on items 6 and 7 if you go from {page: 1, size: 5} to {page: 2, size: 7}.
Lastly, query performance degrades as the table becomes larger. For huge offsets (e.g. OFFSET 1000000) the database still has to read up to those count + offset rows, discard the offset rows and only return the count rows, which results in very poor query performance for large offsets. This is back end knowledge but it's useful to know and you get brownie points for mentioning it.
Cursor-based Pagination
Cursor-based pagination works by returning a pointer/position (a cursor) to the last item in the results. On subsequent queries, the server passes the cursor to the database, and the database knows to return items after that cursor.
This avoids the inaccurate page window problem because new posts added over time do not affect the offset, which is determined by a fixed cursor.
A cursor-based pagination API accepts the following parameters:
| Parameter | Type | Description |
|---|---|---|
size | number | Number of results per page |
cursor | string | An identifier for the last item fetched. The database will know to continue from this item. |
{"pagination": {"size": 10,"next_cursor": "=dXNlcjpVMEc5V0ZYTlo"},"results": [{"id": "123","author": {"id": "456","name": "John Doe"},"content": "Hello world","image": "https://www.example.com/feed-images.jpg","reactions": {"likes": 20,"haha": 15},"created_time": 1620639583}// ... More posts.]}
Facebook, Slack, Zendesk use cursor-based pagination for their developer APIs.
Downsides of cursor-based pagination since you don't know the cursor:
- It's not possible to jump to specific pages with cursors.
In order for the back end to implement cursor-based pagination, the database needs to uniquely map the cursor to a row, which can be done using a database table's primary key.
For an infinite scrolling news feed where:
- New posts can be added frequently to the top of the feed.
- Newly fetched posts are appended to the end of the feed.
- Table size can get grow large really quickly.
Cursor-based pagination is clearly superior to offset-based pagination and it's the most suitable for news feed use cases.
Reference: Evolving API Pagination at Slack
Optimizations and Deep Dive
As there are a few sections within a news feed application, it will be easier to read by focusing on one section at a time and looking at the optimizations that can be done for each section:
- Feed
- Feed Posts
- Post Composer
Feed Optimizations
Rendering Approach
Traditional web applications have multiple choices on where to render the content, whether to render on the server or the client.
- Server-side rendering (SSR): Rendering the HTML on the server side, which is the most traditional way. Best for static content that require SEO and does not require heavy user interaction. Websites like blogs, documentation sites, e-commerce websites are built using SSR.
- Client-side rendering (CSR): Rendering in the browser, by dynamically adding DOM elements into the page using JavaScript. Best for interactive content. Applications like dashboards, chat apps are built using CSR.
Interestingly, news feed applications are somewhere in-between, there's a good amount of static content but they also require interaction. In reality, Facebook uses a hybrid approach which gives the best of both worlds: a fast initial load with SSR then hydrating the page to enable interactions. Subsequent content (e.g. more posts added once the user reaches the end of their feed) will be rendered via CSR.
Modern UI JavaScript frameworks like React and Vue, along with meta frameworks like Next.js and Nuxt enable this.
Read more on Rendering on the web and "Rebuilding our tech stack for the new Facebook.com" blog post.
Infinite Scrolling
Infinite scrolling/feed works by fetching the next set of posts when the user has scrolled to the end of their current loaded feed. This results in the user seeing a loading indicator and a short delay where the user has to wait for the new posts to be fetched and displayed.
A way to reduce or entirely eliminate the waiting time is to load the next set of feed posts before the user hits the bottom of the page so that the user never has to see any loading indicators. A trigger distance of around one viewport height should be sufficient for most cases. The ideal distance is short enough to avoid false positives and wasted bandwidth but also wide enough to load the rest of the contents before the user scrolls to the bottom of the page.
A dynamic distance can be calculated based on the network connection speed and how fast the user is scrolling through the feed.
Implementing Infinite Scroll:
In both approaches, we add a marker element that is rendered at the bottom of the feed.
- Add a
scrollevent listener (ideally debounced) to the page or a timer (viasetInterval) that checks whether the position of the marker element is within a certain threshold from the bottom of the page. The position of the marker element can be obtained usingElement.getBoundingClientRect. - Use the Intersection Observer API to monitor when the marker element is entering or exiting another element or intersecting by a specified amount.
The Intersection Observer API is a browser native API and is preferred over Element.getBoundingClientRect().
The Intersection Observer API lets code register a callback function that is executed whenever an element they wish to monitor enters or exits another element (or the viewport), or when the amount by which the two intersect changes by a requested amount. This way, sites no longer need to do anything on the main thread to watch for this kind of element intersection, and the browser is free to optimize the management of intersections as it sees fit.
Source: Intersection Observer API | MDN
Virtualized Lists
With infinite scrolling, all the loaded feed items are on one single page. As the user scrolls further down the page, more posts are appended to the DOM and with feed posts having complex DOM structure (lots of details to render), the DOM size rapidly increases. As social media websites are long-lived applications (especially if single-page app) and the feed items list can easily grow really long quickly, the number of feed items can be a cause of performance issues in terms of DOM size, rendering, and browser memory usage.
Virtualized lists is a technique to render only the posts that are within the viewport. In practice, Facebook replaces the contents of off-screen feed posts with empty <div>s, add dynamically calculated inline styles (e.g. style="height: 300px") to set the height of the posts so as to preserve the scroll position and add the hidden attribute to them. This will improve rendering performance in terms of:
- Browser painting: Fewer DOM nodes to render and fewer layout computations to be made.
- Virtual DOM reconciliation (React-specific): Since the post is now a simpler empty version, it's easier for React (the UI library that Facebook is using to render the feed) to diff the virtual DOM vs the real DOM to determine what DOM updates have to be made.
Both Facebook and Twitter websites use virtualized lists.
Code Splitting JavaScript for Faster Performance
As an application grows, the number of pages and features increase which will result in more JavaScript and CSS code needed to run the application. Code splitting is a technique to split code needed on a page into separate files so that they can be loaded in parallel or when they're needed.
Generally, code splitting can be done on two levels:
- Split on the page level: Each page will only load the JavaScript and CSS needed on that page.
- Lazy loading resources within a page: Load non-critical resources only when needed or after the initial render, such as code that's only needed lower down on the page, or code that's used only when interacted with (e.g. modals, dialogs).
For a news feed application, there's only a single page, so page-level code splitting is not too relevant, however lazy loading can still be super useful for other purposes. Lazy loading is discussed in more detail under the feed post section as it's most relevant to the feed post UI.
For reference, Facebook splits their JavaScript loading into 3 tiers:
- Tier 1: Basic layout needed to display the first paint for the above-the-fold content, including UI skeletons for initial loading states.
- Tier 2: JavaScript needed to fully render all above-the-fold content. After Tier 2, nothing on the screen should still be visually changing as a result of code loading.
- Tier 3: Resources that are only needed after display that doesn't affect the current pixels on the screen, including logging code and subscriptions for live-updating data.
Source: "Rebuilding our tech stack for the new Facebook.com" blog post
Keyboard Shortcuts
Facebook has a number of news feed-specific shortcuts to help users navigate between the posts and perform common actions, super handy! Try it for yourself by hitting the "Shift + ?" keys on facebook.com.
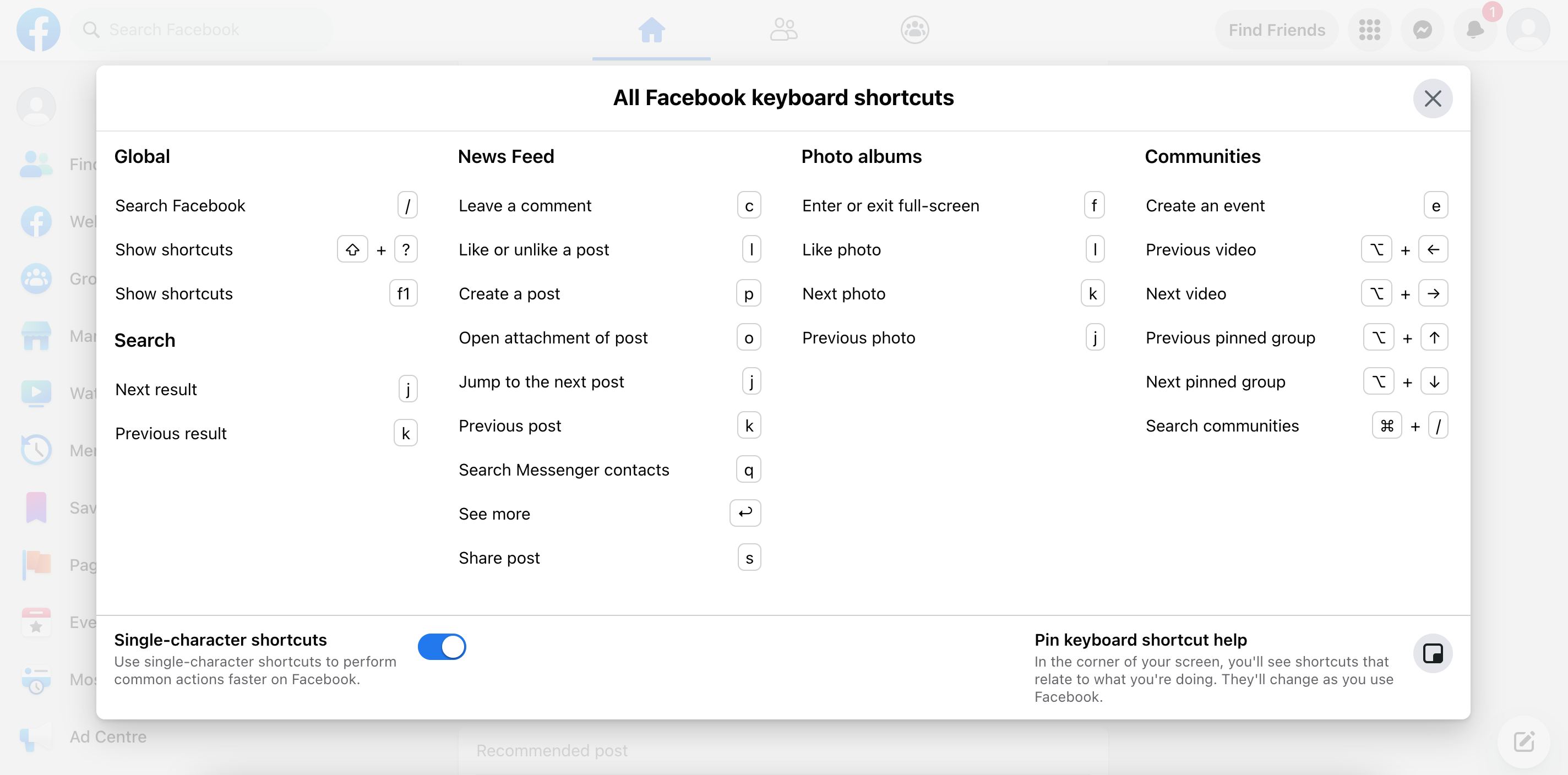
Source: Making Facebook.com accessible to as many people as possible
Loading Indicators
For users who scroll really fast, even though the browser kicks off the request for the next set of posts before the user even reaches the bottom of the page, the request might not have returned yet and a loading indicator should be shown to reflect the request status.
Rather than showing a spinner, a better experience would be to use a shimmer loading effect which resembles the contents of the posts. This looks more aesthetically pleasing and can be used also reduce layout thrash after the new posts are loaded.
An example of Facebook's feed loading shimmer:
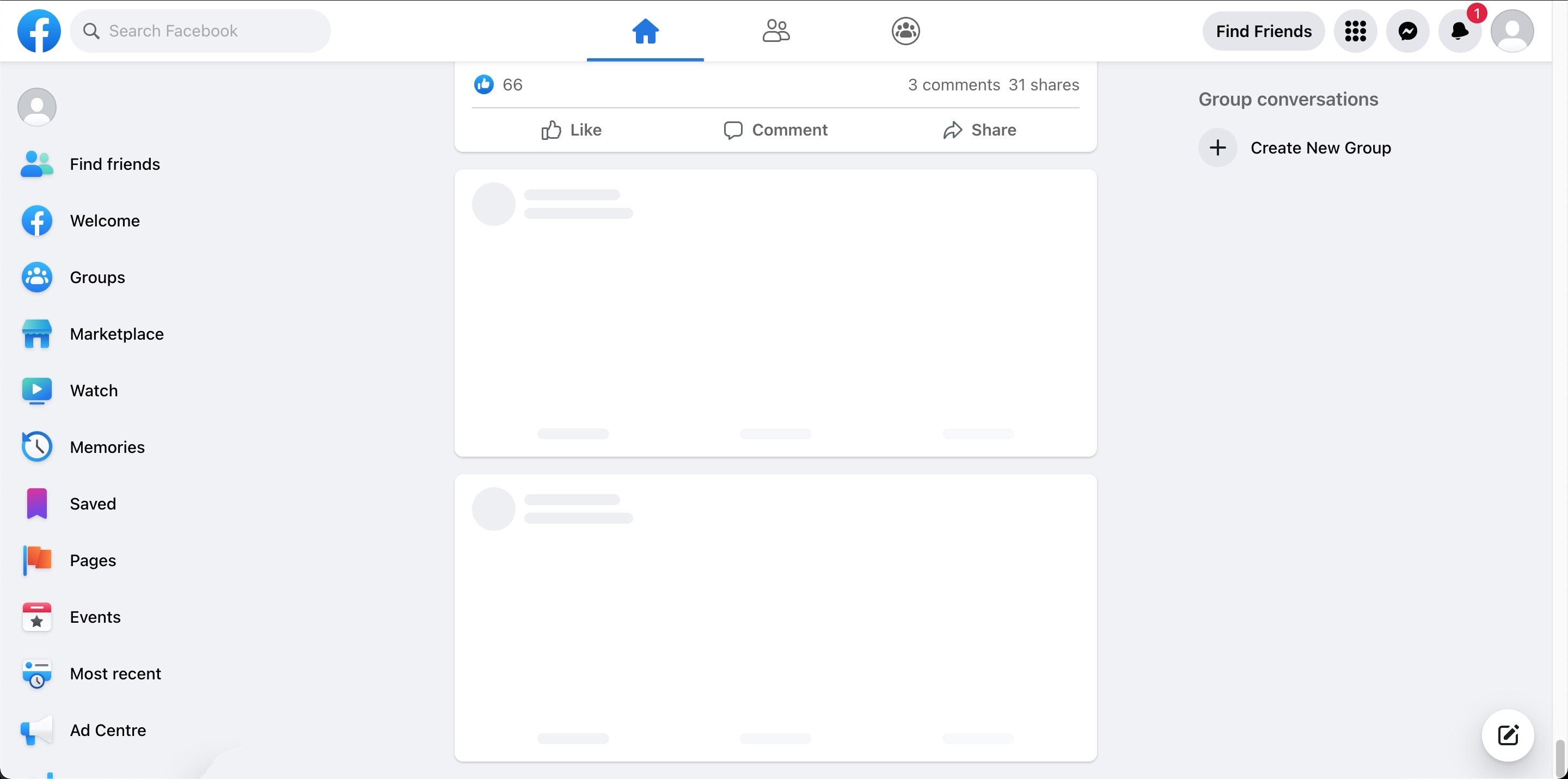
Dynamic Loading Count
As mentioned above in the "Interface" section, cursor-based pagination is more suitable for a news feed. A benefit of cursor-based pagination is that you can change how many items to fetch in subsequent calls. We can use this to our advantage by customizing the number of posts to load based on the browser window height.
For the initial load, we do not know the window height so we need to be conservative and overfetch the number of posts needed. But for subsequent fetches, we know the browser window height and can customize the number of posts to fetch based on that.
Preserving Feed Scroll Position
Feed scroll positions should be preserved if users navigate to another page and back to the feed. This can be achieved in SPAs if the feed posts are cached within the client store along with the scroll position and displayed with that scroll position when the user goes back to the feed page.
Error States
Clearly display error states if the list failed to fetch, or when there's no network connectivity.
Feed Post Optimizations
Delivering Data-driven Dependencies Only When Needed
News feed posts can come in many different formats and require specialized rendering code but not all users will see all of them. One way to achieve this is to have the client load the component JavaScript code for all possible formats upfront so that any kind of feed post format can be rendered. However, this will quickly bloat the page's JavaScript size and there will likely be a lot of unused JavaScript.
Facebook fetches data from the server using Relay, which is a JavaScript-based GraphQL client. Relay couples React components with GraphQL to allow React components to declare exactly which data fields are needed and Relay will fetch them via GraphQL and provide the components with data.
Relay has a feature called data-driven dependencies which delivers component code along with the respective type of data, effectively solving the problem mentioned above. You only load the relevant code when a particular format for a post is being shown.
// Sample GraphQL query to demonstrate data-driven dependencies.... on Post {... on TextPost {@module('TextComponent.js')contents}... on ImagePost {@module('ImageComponent.js')image_data {altdimensions}}}
The above GraphQL query tells the back end to return the TextComponent JavaScript code along with the text contents if the post is a text-based post and return the ImageComponent JavaScript code along with the image data if the post has image attachments. There's no need for the client to load component JavaScript code for all the possible post formats upfront, reducing the initial JavaScript needed on the page.
Source: Rebuilding our tech stack for the new Facebook.com
Rendering Mentions/Hashtags
You may have noticed that textual content within feed posts can be more than plain text. For social media applications, it is common to see mentions and hashtags.
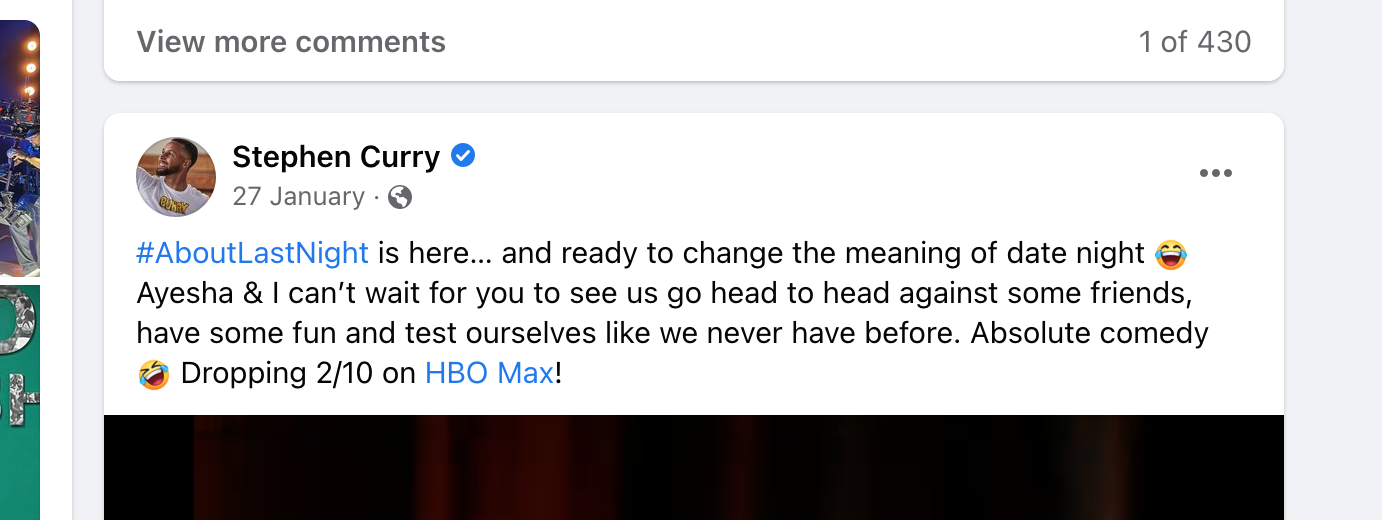
In Stephen Curry's post above, see that he used the "#AboutLastNight" hashtag and mentioned the "HBO Max" Facebook page. His post message has to be stored in a special format such that it contains metadata about these tags and mentions.
What format should the message be so that it can store data about mentions/hashtags? Let's discuss the possible formats and their pros and cons.
HTML Format
The simplest format is HTML, you store the message the way you want it to be displayed.
<a href="...">#AboutLastNight</a> is here... and ready to change the meaning of date night...Absolute comedy 🤣 Dropping 2/10 on <a href="...">HBO Max</a>!
Storing as HTML is usually bad because there's a potential for causing a Cross-Site Scripting (XSS) vulnerability. Also, in most cases it's better to decouple the message's metadata from displaying, perhaps in future you want to decorate the mentions/hashtags before rendering and want to add classnames to the links. HTML format also makes the API less reusable on non-web clients (e.g. iOS/Android).
Custom Syntax
A custom syntax can be used to capture metadata about hashtags and mentions.
- Hashtags: Hashtags don't actually need a special syntax, words that start with a "#" can be considered a hashtag.
- Mentions: A syntax like
[[#1234: HBO Max]]is sufficient to capture the entity ID and the text to display. It's not sufficient to just store the entity ID because sites like Facebook allow users to customize the text within the mention.
Before rendering the message, the string can be parsed for hashtags and mentions using regex and replaced with custom-styled links. Custom syntax is a lightweight solution which is safe yet robust enough if you know beforehand that there will not be new kinds of rich text entities to render in future.
Popular Rich Text Editor Format
Draft.js is a popular rich text editor by Facebook for composing rich text. Draft.js allows users to extend the functionality and create their own rich text entities such as hashtags and mentions. It defines its a custom Draft.js editor state format which is being used by the Draft.js editor.
Draft.js is just one example of a rich text format, there are many out there to choose from. The editor state resembles an Abstract Syntax Tree and can be serialized into a JSON string to be stored. The benefits of using a popular rich text format is that you don't have to write custom parsing code and can easily extend to more types of rich text entities in future. However, these formats tend to be longer strings than a custom syntax version and will result in larger network payload size and require more disk space to store.
An example of how the post above can be represented in Draft.js.
{content: [{type: 'HASHTAG',content: '#AboutLastNight',},{type: 'TEXT',content: ' is here... and ready to change ... Dropping 2/10 on ',},{type: 'MENTION',content: 'HBO Max',entityID: 1234,},{type: 'TEXT',content: '!',},];}
Rendering Images
Since there can be images in a feed post, we can also briefly discuss some image optimization techniques:
- Use a Content Delivery Network (CDN) to host and serve images for faster loading performance.
- Use modern image formats such as WebP which provides superior lossless and lossy image compression.
<img>s should use properalttext.- Facebook provides
alttext for user-uploaded images by using Machine Learning and Computer Vision to process the images and generate a description.
- Facebook provides
- Image loading based on device screen properties
- Send the browser dimensions in the initial request (or subsequent is also fine) and server can decide what image size to return.
- Use
srcsetif there are image processing (resizing) capabilities to load the most suitable image file for the current viewport.
- Adaptive image loading based on network speed
- Devices with good internet connectivity/on WiFi: Prefetch offscreen images that are not in the viewport yet but about to enter viewport.
- Poor internet connection: Render a low-resolution placeholder image and require users to explicitly click on them to load the high-resolution image.
Lazy load code that is not needed for initial render
Many interactions with a feed post are not needed on initial render:
- Reactions popover.
- Dropdown menu revealed by the top-right ellipsis icon button, which is usually meant to conceal additional actions.
The code for these components can be downloaded when:
- The browser is idle as a lower-priority task.
- On demand, when the user hovers over the buttons or clicks on them.
These are considered Tier 3 dependencies going by Facebook's tier definition above.
Optimistic Updates
Optimistic update is a performance technique where the client immediately reflect the updated state after a user interaction that hits the server and optimistically assume that the server request succeeds, which should be the case for most requests. This gives users instant feedback and improves the perceived performance. If the server request fails, we can revert the UI changes and display an error message.
For a news feed, optimistic updates can be applied for reaction interactions by immediately showing the user's reaction and an updated total count of the reactions.
Optimistic updates is a powerful feature built into modern query libraries like Relay, SWR and React Query.
Timestamp Rendering
Timestamp rendering is a topic worth discussing because of a few issues: multilingual timestamps and stale relative timestamps.
Multilingual Timestamps
Globally popular sites like Facebook and Twitter have to ensure their UI works well for different languages. There are a few ways to support multilingual timestamps:
- Server returns the raw timestamp and client renders in the user's language. This approach is flexible but requires the client to contain the grammar rules and translation strings for different languages, which can amount to significant JavaScript size depending on the number of supported languages,
- Server returns the translated timestamp. This requires processing on the server, but you don't have to ship timestamp formatting rules for various languages to the client. However, you cannot update this timestamp on the client.
- Modern browsers can leverage the
Intl.DateTimeFormat()API to transform a raw timestamp into a translated datetime string.
const date = new Date(Date.UTC(2021, 11, 20, 3, 23, 16, 738));console.log(new Intl.DateTimeFormat('zh-CN', {dateStyle: 'full',timeStyle: 'long',}).format(date),);// 2021年12月20日星期一 GMT+8 11:23:16
Relative Timestamps Can Become Stale
If timestamps are displayed using a relative format (e.g. 3 minutes ago, 1 hour ago, 2 weeks ago, etc), recent timestamps can easily go stale especially for applications where users don't refresh the page. A timer can be used to constantly update the timestamps if they are recent (less than an hour old) such that any significant time that has passed will be reflected correctly.
Icon Rendering
Icons are needed within the action buttons of a post for liking, commenting, sharing, etc. There are a few ways to render icons:
| Approach | Pros | Cons |
|---|---|---|
| Separate image | Simple to implement. | Multiple download requests per image. |
| Spritesheet | One HTTP request to download all icon images. | Complicated to set up. |
| Icon fonts | Scalable and crisp. | Need to download the entire font. Flash of unstyled content when font is loading. |
| SVG | Scalable and crisp. Cacheable. | Flickering when file is being downloaded. One download requests per image. |
| Inlined SVG | Scalable and crisp. | Cannot be cached. |
Facebook and Twitter use inlined SVGs and that also seems to be the trend these days.
Source: "Rebuilding our tech stack for the new Facebook.com" blog post
Stale Feeds
It's not uncommon for users to leave their news feed application open as a browser tab and not refresh it at all. It'd be a good idea to prompt the user to refresh or refetch the feed if the last fetched timestamp is more than a few hours ago, i.e. feed is stale.
User Experience
- Truncate posts which have super long message content and reveal the rest behind a "See more" button.
- For posts with large amount of activity (e.g. many likes, reactions, shares), abbreviate counts appropriately instead of rendering the raw count so that it's easier to read and the magnitude is still sufficiently conveyed:
- Good: John, Mary and 103K others
- Bad: John, Mary and 103,312 others
- This summary line can be either constructed on the server or the client. The pros and cons of doing on the server vs the client is similar to the timestamp rendering. However, you should definitely not send down the entire list of users if it's huge as it's likely not needed or useful.
Feed Composer Optimizations
How to render rich text like hashtags and mentions
When drafting a post in the composer, it'd be a nice to have an WYSIWYG editing experience look like the result which contain hashtags and mentions. However, <input>s and <textarea>s only allows input and display of plain text. The contenteditable attribute turns an element into an editable rich text editor.
Try it for yourself here:
This is editable and format-able text thanks to
contenteditable. You can even format the text (e.g. bold by using
Ctrl/Cmd + B).
However, it is not a good idea to use contenteditable="true" as-is in production because it comes with many issues. It'd be better to use battle-tested rich text editor libraries. Facebook has built rich text editors like Draft.js and Lexical and use them for drafting post and comments.
Source: Facebook open sources rich text editor framework Draft.js
Lazy Loading Dependencies
Like rendering news feed posts, users can draft posts in many different formats which require specialized rendering code per format. Lazy loading and can be used to load the resources for the desired formats and optional features in an on-demand fashion.
Non-crucial features that can be lazy loaded on demand:
- Image uploader
- GIF picker
- Emoji picker
- Sticker picker
- Background images
Accessibility
- Feed
- Add
role="feed"to the feed HTML element.
- Add
- Feed Posts
- Add
role="article"to each feed post HTML element. aria-labelledby="<id>"where the HTML tag containing the feed author name has thatidattribute.- Contents within the feed post should be focusable via keyboards (add
tabindex="0") and the appropriatearia-role.
- Add
- Feed interactions
- On Facebook website, users can have more reaction options by hovering over the "Like" button. To allow the same functionality for keyboard users, Facebook displays a button that only appears on focus and the reactions menu can be opened via that button.
- Icon-only buttons should have
aria-labels if there are no accompanying labels (e.g. Twitter).
Bonus: Comments
If time permits and there's time to talk about extra features, we can talk about how comments can be built. In general, the same rules apply to comments rendering and comment drafting:
- Cursor-based pagination for fetching the list of comments.
- Drafting and editing comments can be done in a similar fashion as drafting/editing posts.
- Lazy load emoji/sticker pickers in the comment inputs.
- Optimistic updates
- Immediately reflect new comments by appending the new comment to the existing list of comments.
- Immediately display new reactions and updated reaction counts.
References
- Rebuilding our tech stack for the new Facebook.com
- Making Facebook.com accessible to as many people as possible
- How we built Twitter Lite
- Building the new Twitter.com
- Dissecting Twitter's Redux Store
- Twitter Lite and High Performance React Progressive Web Apps at Scale
- Making Instagram.com faster: Part 1
- Making Instagram.com faster: Part 2
- Making Instagram.com faster: Part 3 — cache first
- Evolving API Pagination at Slack